简介
一、简介
linkedin公司出品,使用scala(spark也是基于此语言)编写,具有高水平扩展和高吞吐量的分布式消息系统。
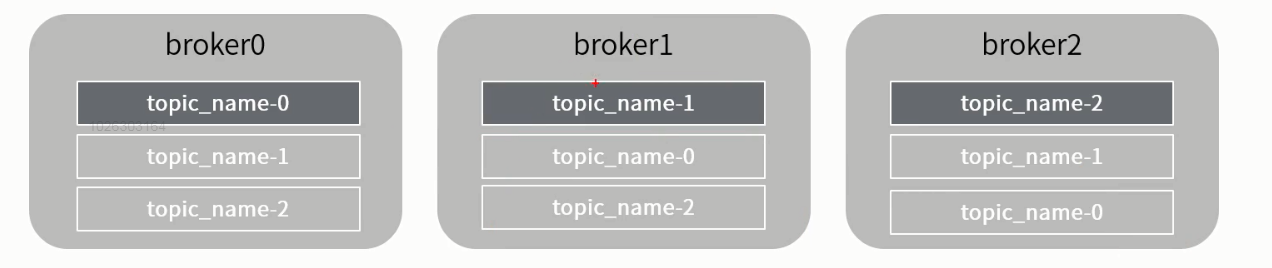
kafka对消息保存根据topic进行分类,集群中实例称之为broker。发送消息者为producer,消息接受者为consumer。
kafka集群、生产者、消费者均需要依赖zookeeper。
1、主流MQ对比
吞吐量 : kafka>rabbitmq>activemq
数据准确性:rabbitmq>activemq>kafka
| ActiveMQ | RabbitMQ | Kafka | |
|---|---|---|---|
| 所属社区/公司 | Apache | Mozilla public license | apache/Linkedin |
| 开发语言 | java | erlang | scala |
| 支持的协议 | OpenWire、STOMP、REST、XMPP、AMQP | AMQP | 仿AMQP |
| 事务 | 支持 | 不支持 | 0.11开始支持 |
| 集群 | 支持(不擅长) | 支持(不擅长) | 支持 |
| 负载均衡 | 支持 | 支持 | 支持 |
| 动态扩容 | 不支持 | 不支持 | 支持(zk) |
2、kafka主要特性
kafka是一个流处理平台:
- 可发布和订阅流数据
- 以容错的方式存储流数据(rabbitmq、activemq不堆积数据,消费完即删。kafka堆积数据,存储数据-使用磁盘顺序存储)
- 可以在流数据产生时就进行处理(kafka内streams api)
kafka适合场景:
- 构造实时流数据管道,系统之间可靠获取数据
- 构建实时流式应用程序,处理流数据或基于数据做出反应
二、相关概念
1、AMQP协议
AMQP: Advanced Message Queuing Protocol,是一个提供统一消息服务的标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件而设计。
模型如下:
**producer** -----*push*------->**broker**-------pull-**------>**consumer** Topic:数据主题,是kafka中用来代表一个数据流的一个抽象。发布数据时,可用topic对数据进行分类,也作为订阅数据时的主题。可同时有多个producer、consumer。
Partition:每个partition是一个顺序的、不可变的record序列,partition中的record会被分配一个自增长的id,我们称之为offset。
kafka顺序消息要求:
1、topic使用一个partition
2、topic多个partition,一类消息使用同一个key即可路由到同一个partition
Record:每条记录都有key、value、timestamp三个消息。
扩展:大数据分片思维
海量数据分片存储在多台服务器中,分片描述、管理需要第三者维护。
统一存储:
提高并发级别:
降低数据丢失的风险:副本解决单点出问题
replication: 副本
每个partition还会被复制到其他服务器作为replication,这是一种冗余备份策略。
- 同一个partition的多个replication不允许出现在同一个broker中
- 每个partition的replication中,有一个leader、零或多个follower
- leader处理此分区所有的读写请求,follower仅仅被动的复制数据
- leader宕机后,会从follower中选举出新的leader
2、kafka核心Api
1、四个核心API
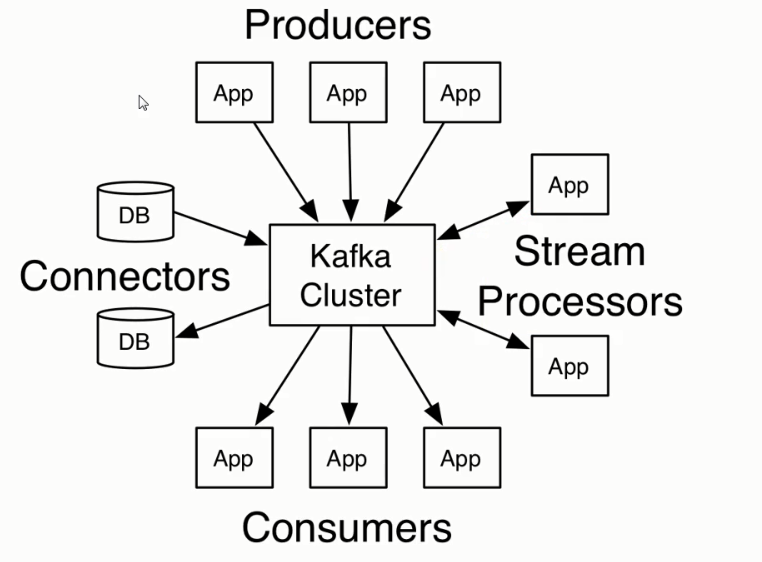
Producer API
允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
Consumer API
允许一个应用程序订阅一个或者多个topic,并且对发布给他们的流式数据进行处理。
Streams API
允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或者多个topic中去,在输入输出流中进行有效的转换。
Connector API
允许构建并运行可重用的生产者或者消费者,将kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系数据库,捕捉表的所有变更内容。
在kafka中,客户端和服务器之间的通信是通过简单、高性能、语言无关的TCP协议完成的。
2、Kafka API-producer
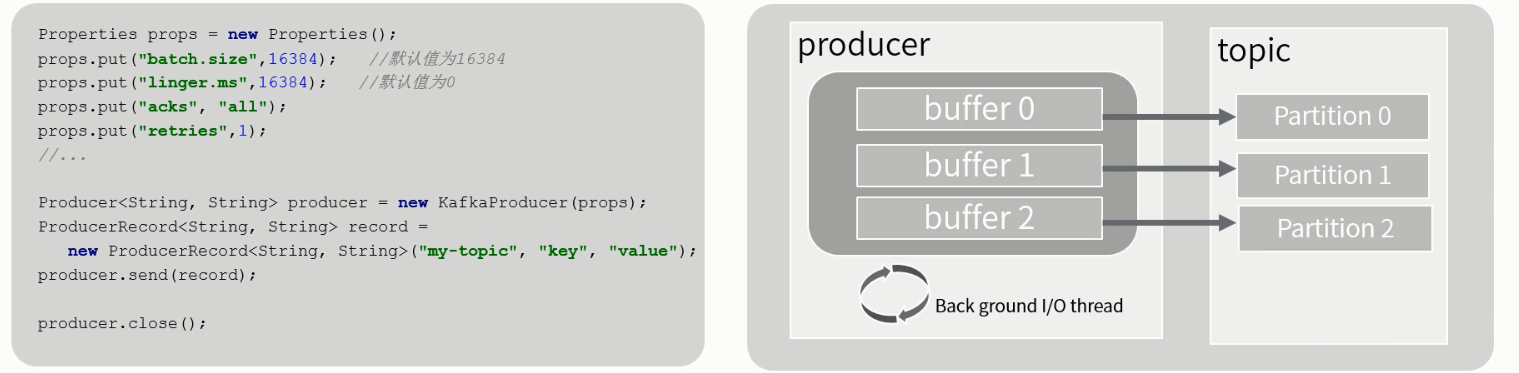
- Producer 会为每个partition维护一个缓冲,用来记录还没有发送的数据,每个缓冲区大小用batch.size指定,默认值为16k
- linger.ms,buffer中的数据还没有达到batch.size前,需要等待的时间
- acks用来配置请求成功的标准 0、1、all
3、Kafka API-consumer
Kafka Simple Consumer
Simple Consumer 位于kafka.javaapi.consumer包中,不提供负载均衡、容错特性,每次获取数据都要指定topic、partition、offset、fetchsize
High-level Consumer
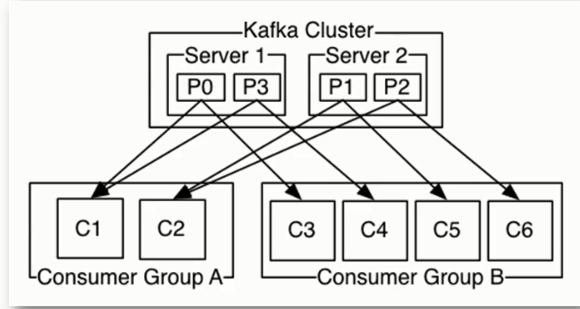
该客户端透明地处理kafka broker异常,透明地切换consumer的partition,通过和broker交互来实现consumer group级别的负载均衡
consumer group是动态维护的,同一个group中的consumer的group id相同
三、kafka使用场景
1、消息系统
2、存储系统
3、日志聚合
ELK=elasticSearch+logstash+kibana4、跟踪网站活动
5、流处理
kafka优雅应用
1.监控工具
Kafka Streams Api
遗留问题解答:offset提交方式:automatic commit、手动提交、本地维护
broker维护的offset是为broker挂了以后重启用的。若不出问题,消费者以自己本地缓存的数据为准。
lambda: 批处理需求, 延时批量处理加流低延迟处理两套,互补;开发与运维成本高
业界流式处理storm。目前流行架构,kafka配合spark或者flink使用。即能批处理又能流式处理,
批处理、流式都是同一套架构开发,解决上面lambda架构问题。
kafka流程序:topic读出数据、处理后、写到新的topic中。
官网stream例子。
数据聚合、清洗轻量级平台
producer分发消息到那个partition中:
producer连上一个broker,元数据列表,有partition的leader分布,
消息key为空时,对partition总数取模;key不为null,对key进行hash后取模。
kafka中key,通过相同key,放在同一个partition中,就不能动态添加partition。
kafka持久化使用磁盘
顺序写+pagecache
磁盘顺序写、raid5磁盘加速
使用pagecache,系统层面缓存。
push和pull的区别:
实时性:push的实时性更好;pull拉取,实时性依赖client的配置和行为
连接方式:push一般长连接,pull短连接
难点:
push,峰值出现在客户端;
pull拉取,实时性和服务端心跳压力的取舍。kafka的long-polling解决此难点,服务端阻塞客户端请求,服务端存在压力,可配置服务端有多少数据即返回、超时时间




